Johannes Staffans
Stop the microservice spaghetti
When moving from a monolithic architecture to microservices, you immediately appreciate the agility with which you can develop new functionality. It's easy to get over-enthusiastic and throw a microservice at any problem you have and not spend much time thinking about the bigger picture. The last thing you want to do is replace the monolithic spaghetti code with a distributed service spaghetti. Here are some of the lessons I've learned over the last year or so of working with microservices and some thoughts about what could have been solved in a better way.
The first thing to realise is that as soon as you start doing microservices, you have traded your monolithic problem for a distributed systems problem with implications for deployment, communication, monitoring and so on. All those things should be carefully thought about. I'm not going into details about deployment this time - suffice to say that microservices should be independently deployable and runnable, ideally as a self-contained thing.
Platform versus distributed services
I recently watched a talk about microservices from GR8Conf 2015 that resonated very well with me. In the talk, two different kinds of microservice architectures are described: platforms and distributed service layers.
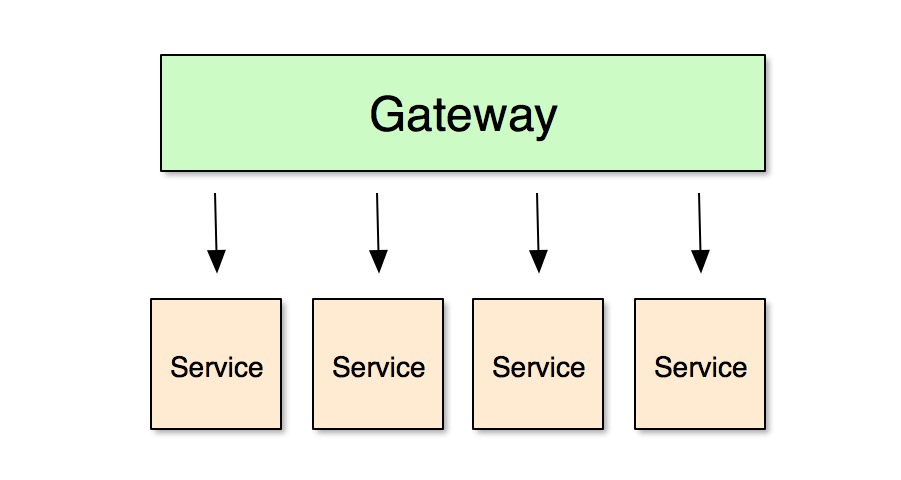
A platform consists of vertically sliced microservices and a gateway layer responsible for orchestrating access to the services — the services themselves do not talk to each other but are instead completely self-contained. This includes having their own domain models, which can be shared with the gateway layer via e.g. a client library, a set of Protobuf message types or something else. The gateway layer is responsible for discoverability and in case of failure, should let any clients know that a particular service is not available. HATEOAS is one way of accomplishing this, the gateway providing a service map as part of its API:
{
"_links": [
{
"rel": "product.reviews",
"href": "/reviews{?productId}"
},
{
"rel": "product.users",
"href": "/users"
}
...
]
}
In a platform architecture, the functionality of various backend services is combined in order to produce a response to a client request. Another kind of microservice architecture is the distributed service layer approach, where services are acting more or less individually in order to accomplish business goals. They may be called by a higher-layer API, by other microservices or maybe directly by clients. This is the case that can easily turn into spaghetti if you are not careful about the interactions between services.
Decoupled distributed services
It's useful to strive for a tree-like architecture, with higher-level services calling lower-level ones in a sort of directed acyclic graph. Anything else will lead to high coupling between services. It's also useful to organise services into two rough camps - services that produce data and other services that consume data.
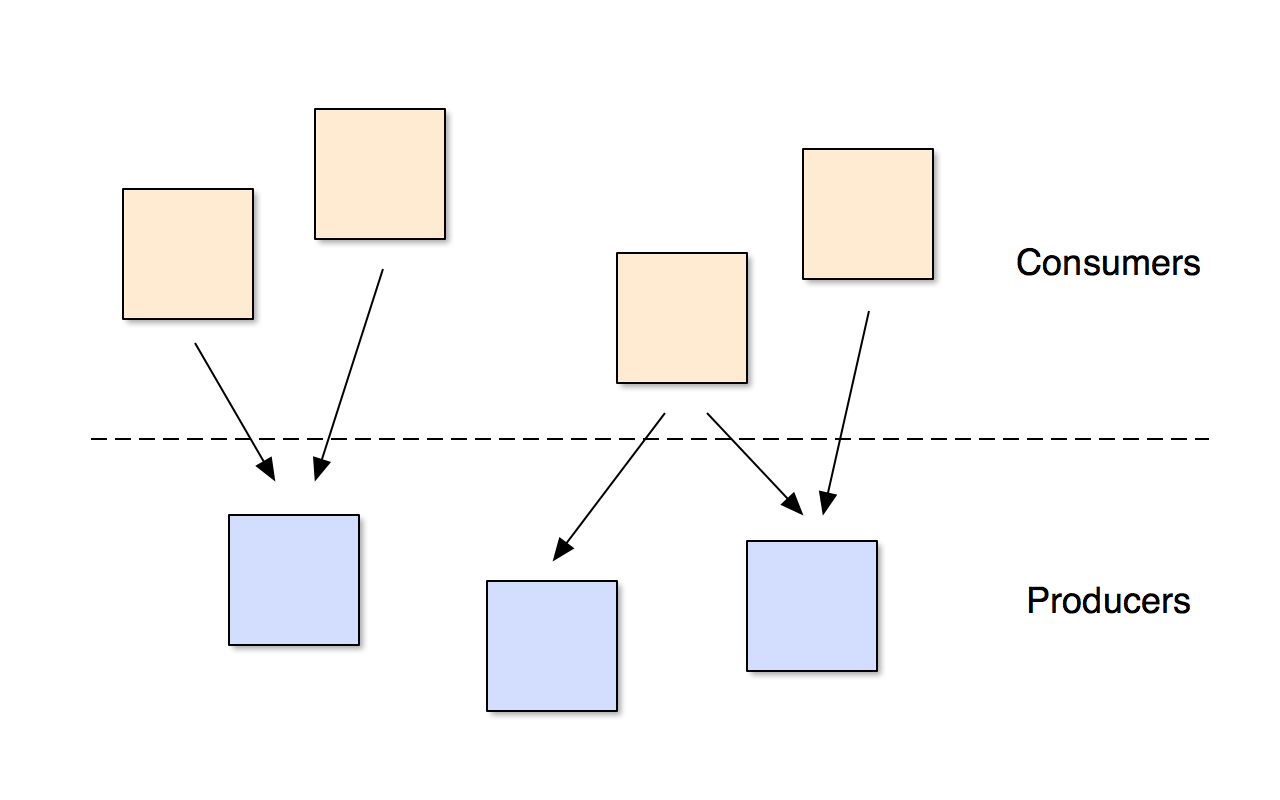
The clients of a particular service should be responsible for understanding its API and provide data in a format that the service expects. API versioning and good documentation help here — sharing a domain model is not such a good idea, because the landscape is more dynamic with any service being able to call basically any other service in the topography.
The above diagram sort of implies RPC being the method of communication between services. In my mind, RPC should however be avoided whenever possible. Communicating using queues (for services where latency is not such a big deal, such an email sending service) or with some distributed messaging scheme should be greatly preferred, because it further decouples services from each other. If you are worried about introducing further overhead in the form of a central message broker, have a look at what your platform already offers — in an AWS landscape, for example, it's possible to build a pub/sub architecture using SQS and SNS. It can be beautifully simple.
As the bane of distributed service communication, look no further than shared database schemas. This introduces extreme coupling between services and makes maintaining the database schema very hard. Avoid at all costs!
Conclusion
This post was more or less a brain dump of my thoughts on how to architect a microservice-based backend. I hope it can work as food for though for anyone embarking on a similar venture. As with any fancy information system, microservices aren't a silver bullet but proper design and some forethought can enable you to reap their full benefit in terms of speed of development, testability and scalability.